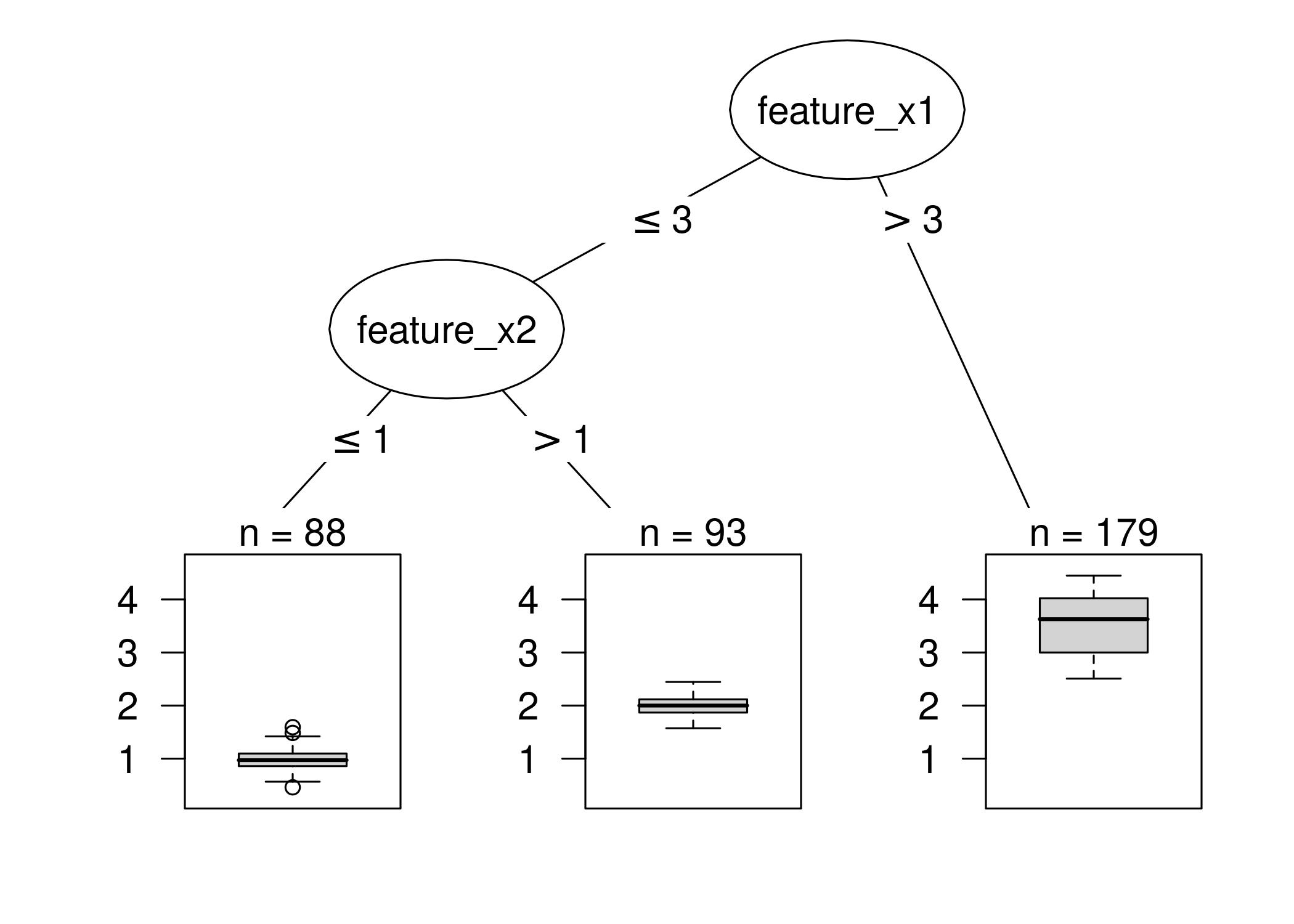
Figür 5.16: Yapay verilerle karar ağacı. Özellik x1 için değeri 3'ten büyük olan örnekler düğüm 5'e ulaşır. Diğer tüm örnekler, özellik x2'nin değeri 1'i aşıp aşmadığına bağlı olarak düğüm 3 veya düğüm 4'e atanır.
Figür 5.16: Yapay verilerle karar ağacı. Özellik x1 için değeri 3'ten büyük olan örnekler düğüm 5'e ulaşır. Diğer tüm örnekler, özellik x2'nin değeri 1'i aşıp aşmadığına bağlı olarak düğüm 3 veya düğüm 4'e atanır.

Figür 5.17: Bisiklet kiralama verileri üzerinde uyarlanmış regresyon ağacı. Ağacın maksimum izin verilen derinliği 2 olarak ayarlandı. Bölünmeler için trend özelliği (2011'den bu yana gün sayısı) ve sıcaklık (temp) seçildi. Kutu grafikleri, terminal düğümdeki bisiklet sayılarının dağılımını gösterir.
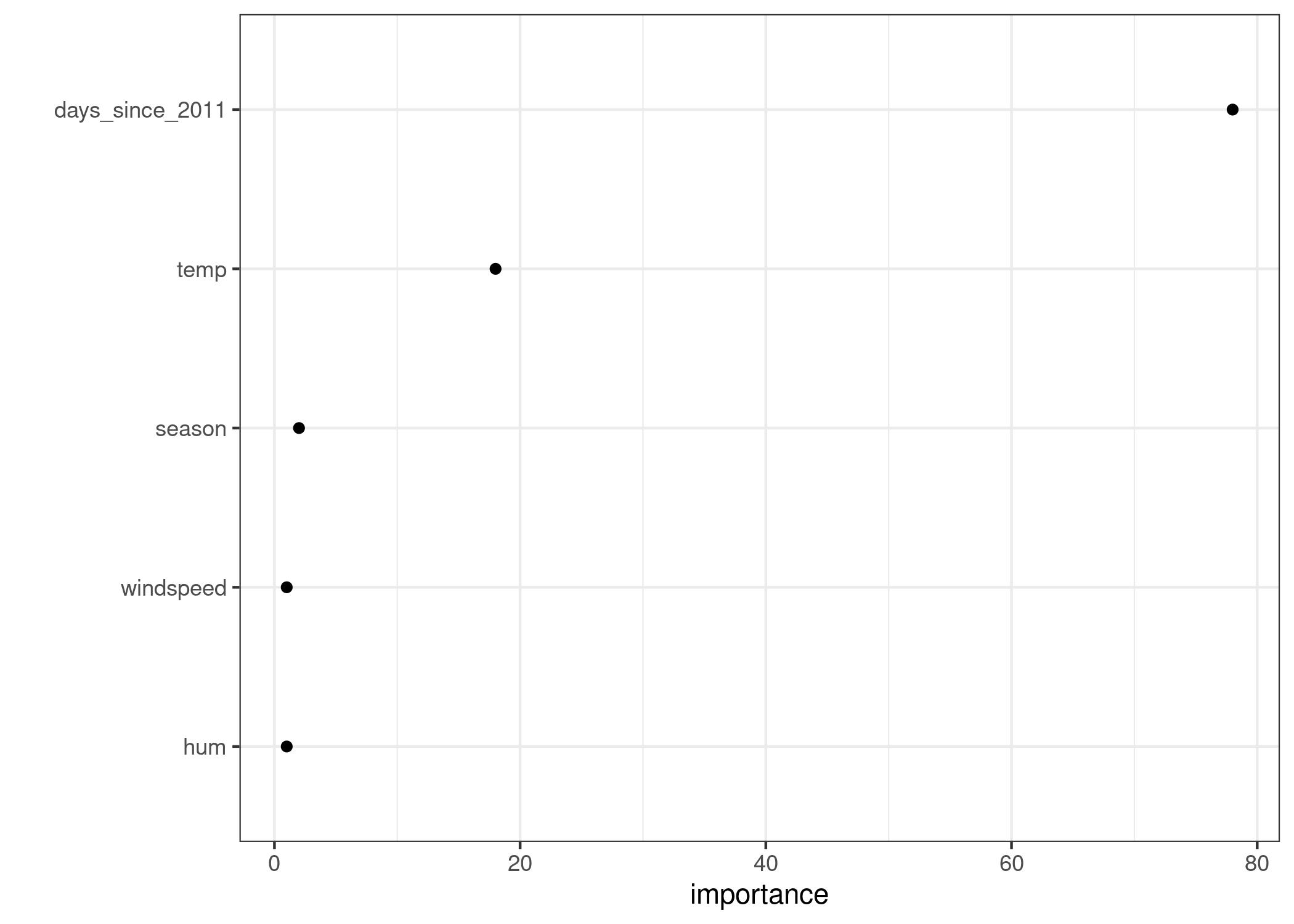
Figür 5.18: Özellik öneminin, düğüm saflığının ortalama olarak ne kadar iyileştirildiği ile ölçüldüğü SHAP özellik önemi.